
Elastic Open WEB Crawler est le nouveau Crawler en version Beta proposé par Elastic et dont le code et la documentation sont disponibles sous Github (https://github.com/elastic/crawler). App Search et Workplace Search standalone sont dépréciés en version 9 (https://www.elastic.co/blog/search-for-enterprise-serverless) et donc Elastic Open Web Crawler est le remplaçant naturel de App Search Web Crawler (https://www.elastic.co/guide/en/app-search/8.18/web-crawler.html).
Contrairement à son prédécesseur, ce nouveau crawler n’est pas intégré à Kibana et il doit être configuré avec amour avec des fichiers YAML et lancé en ligne de commande.
Elastic Open Web Crawler est compatible avec Elasticsearch 8 et 9. Le résultat du crawl peut être envoyé soit directement vers elasticsearch ou Logstash, soit vers des fichiers JSON.
Les fonctionnalités principales de Elastic Open Crawler sont :
- Règles de parcours des sites
- Règles d’extraction des données dans les pages ou dans les URL
- Extraction de données binaires (fichiers PDF, WORD, …)
- Indexation directe dans elasticsearch ou écriture dans des fichiers JSON
- Configuration technique (parallélisation du crawl, taille de la file d’attente, timeout, gestion des problématiques de protocole HTTP, …)
- Personnalisation du User-Agent présenté aux sites
- Authentification sur les sites
Dans cet article, je vais décrire les étapes de mise en œuvre de Elastic Open Web Crawler avec Docker en générant des fichiers JSON afin de pouvoir effectuer des post-traitements sur ces fichiers avant leur indexation dans elasticsearch.
La finalité de l’utilisation de Elastic Open Crawler est de disposer de données orientées « texte » sur des sujets variés en Anglais et en Français. Il sera ainsi possible d’explorer entre autres les fonctionnalités orientées IA d’elasticsearch.
Pour l’exemple, le crawl va concerner le site www.20minutes.fr pour la rubrique high-tech. Les étapes sont :
- Configuration du crawler pour un site spécifique
- Envoi vers fichiers
- Règles de parcours des urls
- Règles d’extraction des données des pages: date de publication, auteurs et ciblage plus précis du contenu principal des pages
- Lancement du crawl avec Docker
- Post-traitement
- Prettify des fichiers JSON (optionnel pour visualiser les fichiers générés)
- Extraction plus précise des données présent dans les fichiers JSON au moyen d’un script Python
- Extraction de la date de publication de la page si récupéré par la règle d’extraction
- Remplacement body par le contenu principal si récupérer par la règle d’extraction
- Enrichissement des données présentes dans les fichiers JSON au moyen d’un script Python (optionnel)
- NER
- Parser le raw HTML des pages afin de pouvoir en extraire le contenu pertinent avec des librairies comme python-readability par exemple
- Indexation dans elasticsearch
- Configuration du template (mapping)
Pré-Requis
Les pré-requis pour réaliser les manipulations décrites dans cet article sont de disposer de versions récentes de Git, Docker et Python. Il faut ensuite récupérer les sources sur Github et démarrer une stack elasticsearch.
Récupération des sources pour la mise en pratique
Dans un répertoire de travail, récupérer le code des exemples.
$ git clone git@github.com:bejean/es-labs.git
$ cd es-labs
$ git checkout tags/article-crawler-20250618 -b article-crawler-20250618
Initialisation de l’environnement python.
$ cd scripts
$ python3 -m venv .venv
$ source .venv/bin/activate
$ pip install --upgrade pip
$ pip install -r requirements.txt
$ cd ..
Démarrage de elasticsearch & Kibana
Pour les manipulations, il est possible de démarrer d’une stack elasticsearch au moyen du script start-local (https://github.com/elastic/start-local).
$ curl -fsSL https://elastic.co/start-local | sh
Bien noter le mot de passe de l’utilisateur elastic qui est affiché et après le démarrage, vous pouvez le modifier
$ docker exec -it es-local-dev ./bin/elasticsearch-reset-password -i -u elastic
This tool will reset the password of the [elastic] user.
You will be prompted to enter the password.
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]: xxxxx
Re-enter password for [elastic]: xxxxx
Password for the [elastic] user successfully reset.
Et remplacer le mot de passe dans le fichier .env
sed 's/^ES_LOCAL_PASSWORD=.*/ES_LOCAL_PASSWORD=xxxxx/' .env
Configuration du crawler
La configuration du crawler est faite au moyen d’un fichier YALM. Pour notre exemple, le fichier crawler/config/crawl-20-minutes-tech.yml est utilisé. Il permet de crawler la rubrique high-tech du site 20minutes.fr. D’autres exemples sont disponibles.
Les éléments de configuration :
- Cible du crawl : Le crawl est configuré pour un domaine unique, ici https://www.20minutes.fr, avec https://www.20minutes.fr/high-tech/ comme URL de départ.
- Profondeur de crawl : Une profondeur maximale de 2 est définie, ce qui est généralement suffisant pour couvrir la globalité d’un site.
- Règles de parcours : Des règles d’acceptation et de rejet des URLs sont définies. L’ordre des règles est crucial, car la première règle correspondante est appliquée. Dans cet exemple, seules les URLs sous /high-tech sont autorisées.
- Règles d’extraction : Pour les URLs commençant par /high-tech, des données spécifiques sont extraites en utilisant des chemins XPATH:
- publication_date : La date de publication de l’article.
- author : Les auteurs de l’article.
- article : Le contenu principal de la page.
- Destination des données : Les données crawlées sont envoyées vers des fichiers JSON. Cela permet un post-traitement des fichiers avant leur indexation. L’option full_html_extraction_enabled est désactivée pour ne pas conserver le contenu HTML brut.
- Répertoire de sortie : Les fichiers JSON sont stockés dans le répertoire /output/20-minutes-high-tech.
- Paramètres complémentaires : Des limites de taille sont spécifiées pour le titre, le corps, les mots-clés, la description et le nombre de liens indexés, …
# Configuration du domaine et des url de
# démarrage du crawl
domains:
- url: https://www.20minutes.fr
seed_urls:
- https://www.20minutes.fr/high-tech/
# Règles d'acceptation et de rejet des url.
# Seule les urls sous /high-tech sont acceptées
# L'ordre est important car la première règle qui correspond
# à l'url courante est appliquée
crawl_rules:
- policy: allow
type: begins
pattern: /high-tech
- policy: deny
type: regex
pattern: .*
# Les règles d'extraction des données des pages
# Pour les url qui commence par /high-tech, on essaye
# dans cet exemple d'extraire la date de publication,
# les auteurs et le contenu principal
# de la page.
# Les éléments sont ciblés pas leur chemin XPATH
extraction_rulesets:
- url_filters:
- type: begins
pattern: /high-tech
rules:
- action: extract
field_name: publication_date
selector: //*[@id="page-content"]/.../time
join_as: string
value: yes
source: html
- action: extract
field_name: author
selector: //*[@id="page-content"]/.../p[1]
join_as: array
value: yes
source: html
- action: extract
field_name: article
selector: //*[@id="page-content"]/.../div[2]
join_as: string
value: yes
source: html
# Où sont envoyées les données crawlées. Possible values sont :
# console, file, or elasticsearch
output_sink: file
# Il est possible de conserver le contenu brut de la page
# dans l'élément "full_html" des fichiers JSON produits.
# Ceci est intéressant pour des post traitements
# spécifiques full_html_extraction_enabled: false
# Le répertoire destination des fichiers JSON produits
output_dir: /output/20-minutes-high-tech
# La profondeur maximale de crawl. Par expérience,
# une profondeur de 2 ou 3 permet généralement de récupérer
# la totalité d'un site.
max_crawl_depth: 2
# Quelques paramètres complémentaires
max_title_size: 500
max_body_size: 5_242_880 # 5 megabytes
max_keywords_size: 512
max_description_size: 512
max_indexed_links_count: 5
max_headings_count: 5
L’ensemble des paramètres sont décrits ici :
https://github.com/elastic/crawler/blob/main/docs/CONFIG.md
https://github.com/elastic/crawler/blob/main/config/crawler.yml.example
Lancement du crawl avec Docker
Le lancement du crawl est fait sous Docker au moyen du script crawler/crawl.sh
$ crawler/crawl.sh -c crawler/config/crawl-20-minutes-tech.yml -o data/output
Le script se charge de configurer et monter les volumes pour rendre accessibles au container les fichiers de configuration et le répertoire destination des fichiers JSON.
Durant le crawl le taille de la file d’attente des url à traiter est affichée (queue_size), ce qui permet de suivre l’avancement.
Post-traitements
Pour vérifier le résultat du crawl, il est pratique de rendre lisibles les fichiers JSON générés
$ crawler/prettify_json.sh data/output/20-minutes-high-tech
Le script de post-traitements réalise les tâches suivantes :
- Extraction de la date de publication de la page si récupérer par la règle d’extraction
- Amélioration des auteurs récupérés par la rêgle d’extraction
- Remplacement du contenu de l’élément body par celui de l’élément article si ce dernier a été créé par la règle d’extraction du contenu pertinent de l’article
- Création de fichiers JSON qui regroupent plusieurs documents (10)
$ ./scripts/crawler_post_process.sh -i data/output/20-minutes-high-tech
Les fichiers JSON générés sont localisés dans le sous répertoire « clean » du répertoire d’entrée.
Avant indexation dans elasticsearch, d’autres enrichissements des données pourraient être réalisés comme par exemple l’extraction d’entités nommées (NER) avec des modèles spécifiques à la langue et aux sujets traités par les articles. Cela fera sans doute l’objet d’un article ultérieur.
Indexation dans elasticsearch
Lancement d’une stack elasticsearch au moyen par exemple du script start-local (https://github.com/elastic/start-local).
Lors d’une indexation directe dans elasticsearch, un mapping minimaliste par défaut est défini lors de la création de l’index au moment de l’indexation du premier document. Si un mapping spécifique doit être mis en place, il est nécessaire de le faire avant l’envoi du premier document dans l’index. Par contre, lors de l’envoie des documents JSON par un script externe au crawler, aucun mapping n’est mis en place. Mettre en place ce mapping est un pré-requis.
Création du template dans elasticsearch
Le template est disponible dans le fichier elasticsearch/es-crawler-template-minimal.json. Ce template spécifie un index_patterns »: [« crawler-*] ». Il est dérivé du mapping mis en place par le crawler lorsque ce dernier index directement dans elasticsearch. Il s’agit d’un template très basique à faire évoluer en fonction des besoins.
$ curl -X PUT http://localhost:9200/_template/crawler \
-k -u "elastic:elastic" \
-H "Content-Type: application/json" \
-d @elasticsearch/es-crawler-template-minimal.json
Lancer l’indexation
$ ./scripts/elasticsearch_indexer.sh \
--input data/output/20-minutes-high-tech/clean \
--index crawler-20-minutes-high-tech \
--host http://localhost:9200 \
--user elastic \
--password elastic
Le script indique le traitement de chaque fichier JSON et le découpage en bulk.
Lorsque l’indexation est terminée, les données sont disponibles en recherche avec elasticsearch ou dans Kibana.
Rechercher dans Kibana
Création d’un Data view
On va passer par l’API pour créer un Data View et utiliser le champ publication_date comme Time field.
curl -X POST "http://localhost:5601/api/data_views/data_view" \
-H "Content-Type: application/json" \
-H "kbn-xsrf: true" \
-d '{
"data_view": {
"title": "crawler-20-minutes-high-tech",
"name": "crawler-20-minutes-high-tech",
"timeFieldName": "publication_date"
}
}' \
-k -u elastic:elastic
La date de publication récupérée par la règle d’extraction et remise en forme en post-traitement est ainsi utilisée pour l’histogramme.
Navigation dans Kibana Discover

On remarque l’aggrégation sur les auteurs. Tout comme la date de publication, les auteurs ne sont pas une information extraite par le crawler par défaut mais ils ont été récupérés par la règle d’extraction.
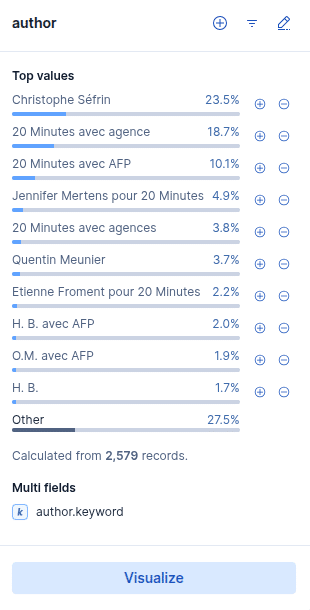
La mise en place d’une régle simple de post-traitement des auteurs permet de nettoyer les valeurs.

Conclusions
Dans cet article, j’ai proposé une mise en œuvre de Elastic Open Crawler afin de collecter des données sur différents sites WEB, de réaliser quelques premières améliorations des données collectées et enfin de les indexer dans elasticsearch.
Elastic Open Crawler est un outil simple. Il est encore jeune et en pleine évolution et voici quelques améliorations qui seraient bien pratiques :
- Organiser les fichiers dans une arborescence de répertoires et non pas dans un répertoire unique qui pourrait très vite contenir devenir trop volumineux.
- Ajouter une commande de test sur une url spécifique pour valider les règles