Dans un précédent article, j’ai présenté l’Elastic Open Web Crawler et montré comment collecter des publications issues de sites de presse. J’ai proposé quelques post-traitements simples avant l’indexation dans elasticsearch afin d’extraire un contenu plus propre et des informations comme la date de publication ou les auteurs.
Dans ce nouvel article, toujours sur la base des articles crawlés, j’explore différentes solutions d’extraction d’entités nommées (NER) pour l’enrichissement de données destinées à l’indexation dans des moteurs de recherche comme Elasticsearch ou Solr. L’accent est mis sur les données en français. Les méthodes étudiées incluent l’extraction via Elasticsearch, ainsi que des approches qui utilisent spaCy, spaCy-LLM, Hugging Face Transformers et Flair.
Les deux approches testées sont :
- Extraction par elasticsearch avec un pipeline d’indexation et un processeur “inference” et l’utilisation d’un des modèles supportés
- Hors Elasticsearch :
- transformers Hugging Face
- spaCy
- spaCy-LLM
- Flair
- elasticsearch et son API d’inférence (et pourquoi pas ?)
Les critères de choix de la solution à mettre en œuvre seront bien évidemment la qualité des entités extraites, les avantages et inconvénients des deux approches et les contraintes techniques et de coûts.
Pre-requis
Les pré-requis pour réaliser les manipulations décrites dans cet article sont de disposer de versions récentes de git, docker et python.
Drivers GPU
Les librairies python utilisées peuvent exploiter la GPU de la carte graphique. Selon l’ordinateur et le système d’exploitation, la procédure d’installation des drivers peut varier. Sous Ubuntu 22.04, j’ai appliqué la procédure décrite dans cet article : https://www.cyberciti.biz/faq/ubuntu-linux-install-nvidia-driver-latest-proprietary-driver/. De même afin que des containers Docker exploitent les GPU Nvidia, j’ai suivi cette procédure : https://dev.to/thenjdevopsguy/using-nvidia-gpus-with-docker-in-5-minutes-386g.
Récupération des sources
Les sources des scripts utilisés dans cet arcticle sont à récupérer sur Github
$ git clone git@github.com:bejean/es-labs.git
$ cd es-labs
$ git checkout tags/article-ner-202500703 -b article-ner-202500703
Initialisation de l’environnement python.
$ cd scripts
$ python3 -m venv .venv
$ source .venv/bin/activate
$ pip install --upgrade pip
$ pip install -r requirements.txt
$ python -m spacy download fr_core_news_sm
$ python -m spacy download fr_core_news_lg
$ cd ..
Stack elasticsearch
Il est nécessaire de disposer d’une stack elasticsearch. Pour cela, j’utilise le script start-local https://github.com/elastic/start-local. Voir le détail de la mise en place dans l’article Elastic Open WEB Crawler : https://www.eolya.fr/elastic-open-web-crawler/
Les données
Pour terminer, il est nécessaire de disposer des données issues d’un crawl du site 20 Minutes. Il faut donc lire et appliquer les manipulations de l’article Elastic Open WEB Crawler : https://www.eolya.fr/elastic-open-web-crawler/
Extraction des entités par elasticsearch au moment de l’indexation
Pour tester les 3 modèles qui semblent des plus appropriés, on les installe au moyen de Eland qui est l’outil développé par Elastic afin de faciliter l’intégration entre Elasticsearch et les modèles de machine learning.
Les 3 modèles testés sont :
- BERT base NER
- DistilBERT base cased finetuned conll03 English
- DistilRoBERTa base NER conll2003
Déploiement des 3 modèles NER dans Elasticsearch
docker run -it --rm --net=host docker.elastic.co/eland/eland \
eland_import_hub_model \
--url http://localhost:9200 \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner \
-u elastic -p elastic \
--start
docker run -it --rm --net=host docker.elastic.co/eland/eland \
eland_import_hub_model \
--url http://localhost:9200 \
--hub-model-id dslim/bert-base-NER \
--task-type ner \
-u elastic -p elastic \
--start
docker run -it --rm --net=host docker.elastic.co/eland/eland \
eland_import_hub_model \
--url http://localhost:9200 \
--hub-model-id philschmid/distilroberta-base-ner-conll2003 \
--task-type ner \
-u elastic -p elastic \
--start
A la fin du déploiement du modèle, son id dans elasticsearch est affiché.
2025-07-01 06:37:34,293 INFO : Starting model deployment
2025-07-01 06:37:37,216 INFO : Model successfully imported with id 'dslim__bert-base-ner'
Il est également possible de le fixer avec l’option –es-model-id
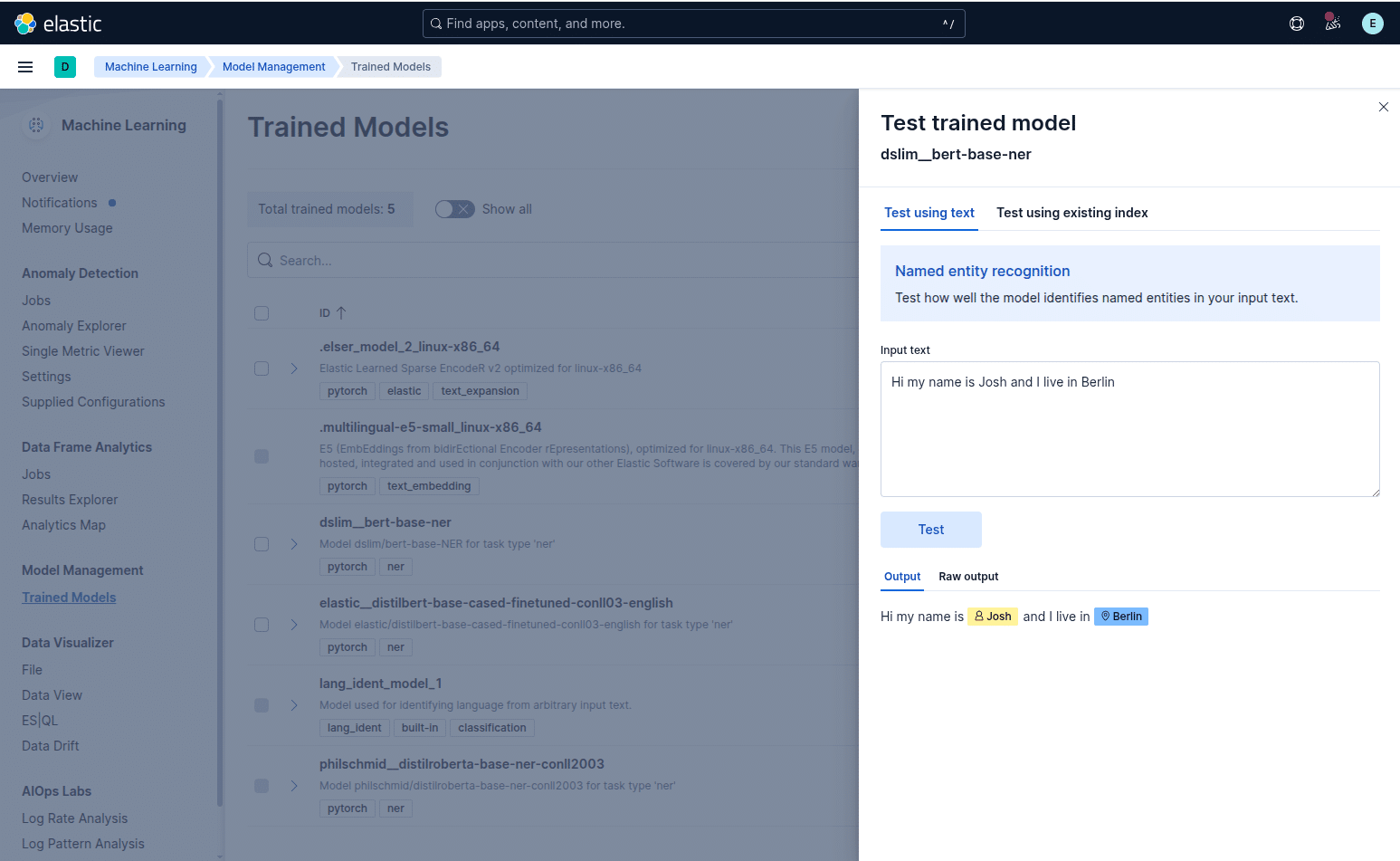
Il est possible de tester dans Dev Tools l’extraction des entitées nommées avec l’API inference
POST _ml/trained_models/dslim__bert-base-ner/_infer
{
"docs": [
{
"text_field": "Hi my name is Josh and I live in Berlin"
}
]
}
{
"inference_results": [
{
"predicted_value": "Hi my name is [Josh](PER&Josh) and I live in [Berlin](LOC&Berlin)",
"entities": [
{
"entity": "Josh",
"class_name": "PER",
"class_probability": 0.9991300933246934,
"start_pos": 14,
"end_pos": 18
},
{
"entity": "Berlin",
"class_name": "LOC",
"class_probability": 0.999493376483773,
"start_pos": 33,
"end_pos": 39
}
]
}
]
}
Ou dans Kibana
Création d’un ingest pipeline
L’extraction des entités nommées lors de l’indexation se fait avec un ingest pipeline et un « inference » processor.
Pour l’exercice, on choisit le modèle « philschmid/distilroberta-base-ner-conll2003 » qui a pour id « philschmid__distilroberta-base-ner-conll2003 ». Le but est d’alimenter un ensemble de champs « tags.* » à partir des entitées nommées extraites.
Les processors :
- script : pour concaténer les champs « title » et « meta_description » dans le champ « ner_field »
- inference : pour calculer les entitées et les envoyer dans le champ « ml.ner »
- script : pour alimenter les champs « tags.PER », « tags.LOC », …
- remove : pour supprimer le champ « ml »
- remove : pour supprimer le champ « ner_field »
{
"description": "NER pipeline",
"processors": [
{
"script": {
"description": "Concatenate fields for NER input",
"lang": "painless",
"source": "String title = ctx.containsKey('title') ? ctx.title + '.' : ''; String desc = ctx.containsKey('meta_description') ? ctx.meta_description : ''; ctx.ner_field = title + ' ' + desc;"
}
},
{
"inference": {
"model_id": "philschmid__distilroberta-base-ner-conll2003",
"target_field": "ml.ner",
"field_map": {
"ner_field": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
},
{
"remove": {
"field": "ml"
}
},
{
"remove": {
"field": "ner_field"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Le pipeline est disponible dans le fichier « elasticsearch/es-crawler-pipeline-ner.json ». Sa mise en place dans elasticsearch avec curl et d’un appel à l’API.
$ curl -X PUT http://localhost:9200/_ingest/pipeline/crawler-ner \
-k -u "elastic:elastic" \
-H "Content-Type: application/json" \
-d @elasticsearch/es-crawler-pipeline-ner.json
Mise en place d’un mapping
Par défaut les champs « tags.* » sont de type keyword. Si on souhaite disposer d’une indexation de type text et keyword, on spécifie le mapping correspondant.
Au moyen d’un template, on associe un index-pattern par défaut « crawler_ner-* » à ce mapping
"tags.MISC": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"tags.ORG": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"tags.PER": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"tags.LOC": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
Le template complet est disponible dans le fichier « elasticsearch/es-crawler-template-ner.json ». Sa mise en place dans elasticsearch avec curl et d’un appel à l’API.
$ curl -X PUT http://localhost:9200/_template/crawler-ner \
-k -u "elastic:elastic" \
-H "Content-Type: application/json" \
-d @elasticsearch/es-crawler-template-ner.json
Indexation des articles
Avec le script présenté dans le précédent article « Elastic Open WEB Crawler », on lance l’indexation des fichiers récupérés avec le crawler et on indique un nom d’index qui commence par « crawler_ner-« . On spécifie le pipeline « crawler-ner » et une une taille de bulk minimale sous peine de time-out.
$ ./scripts/elasticsearch_indexer.sh \
--input data/output/20-minutes-high-tech/clean \
--index crawler_ner-20-minutes-high-tech \
--pipeline crawler-ner \
--host http://localhost:9200 \
--user elastic \
--password elastic \
--bulk_size 2
Création d’un Data view
On va passer par curl et un appel à l’API pour créer un Data View et utiliser le champ publication_date comme Time field.
curl -X POST "http://localhost:5601/api/data_views/data_view" \
-H "Content-Type: application/json" \
-H "kbn-xsrf: true" \
-d '{
"data_view": {
"title": "crawler_ner-20-minutes-high-tech",
"name": "crawler_ner-20-minutes-high-tech",
"timeFieldName": "publication_date"
}
}' \
-s \
-k -u elastic:elastic
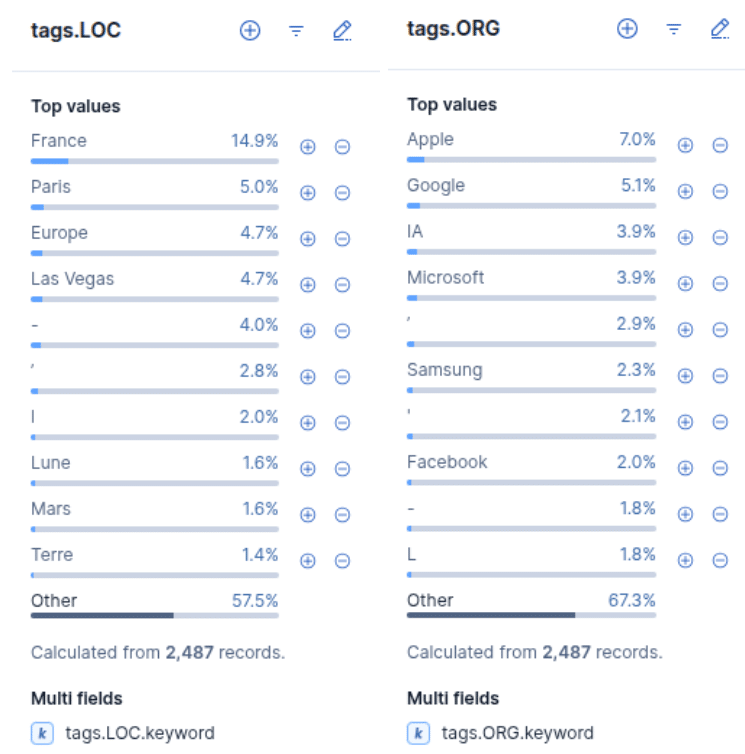
La date de publication récupérée lors du crawl par une règle d’extraction et une remise en forme en post-traitement est utilisée pour l’histogramme.
Suite à l’indexation, les résultats obtenus pour les entités sont plutôt décevants. Il y a sans doute un post-traitement à mettre en place dans le pipeline.
Extraction des entités hors de elasticsearch avant l’indexation
L’alternative à l’extraction des entités nommées par elasticsearch au moment de l’indexation est de réaliser cette tâche en amont et d’enrichir les documents JSON issus du crawl. Nous allons présenter différentes techniques.
- spaCy (https://spacy.io/)
Il s’agit d’une librairie Python open source de traitement du langage naturel (NLP), conçue pour l’analyse de textes, l’extraction d’informations et l’entraînement de modèles linguistiques. - spaCy-LLM
Il s’agit d’une extension de spaCy qui permet d’intégrer facilement des grands modèles de langage (LLMs) comme GPT ou LLaMA dans des pipelines NLP pour des tâches telles que l’extraction d’entités, la classification ou la génération de texte. - Transformers de Hugging Face (https://huggingface.co/docs/inference-providers/tasks/index)
Transformers de Hugging Face est une librairie Python ou Javascript open source qui utilise des modèles pré-entraînés pour le traitement du langage naturel, basés sur l’architecture Transformer (comme BERT, GPT, RoBERTa), faciles à utiliser pour des tâches comme la classification, la génération de texte ou l’extraction d’entités. - Flair (https://github.com/flairNLP/flair)
Flair est une librairie Python open source développée par Zalando pour réaliser des tâches telles que l’extraction d’entités, la classification de texte et le POS tagging. - elasticsearch
Depuis la version 8, Elasticsearch permet d’intégrer des modèles LLM pour des tâches comme la classification, l’extraction d’entités ou l’embedding de texte. Il est compatible avec des modèles locaux ou hébergés et fournit une API d’inférence.
Scripts Python de tests
Pour tester ces techniques, j’ai développé un script Python « scripts/crawler_post_process_ner.py » et un module « nlp_ner ». Ce script peut soit enrichir les fichiers JSON issue du crawl, soit consolider dans un fichier CVS le résultat de l’extraction. Ce fichier CSV indique le nombre d’occurrences trouvées de chaque entité. Les fichiers CSV générés pour chaque méthode sont disponibles dans le dossier « tests/ner ».
Le module « nlp_ner » fournit une factory pour créer un objet « nlp » en fonction du mode « spacy », « spacy_llm », …
match ner_mode:
case 'spacy':
nlp = NlpNerFactory.build("spacy",
model=ner_model)
case 'spacy_llm':
nlp = NlpNerFactory.build("spacy_llm",
config_file=ner_config_file)
case 'transformers':
nlp = NlpNerFactory.build("transformers",
model=ner_model,
score_threshold=score_threshold)
case 'flair':
nlp = NlpNerFactory.build("flair",
model=ner_model,
score_threshold=score_threshold)
case 'elasticsearch':
nlp = NlpNerFactory.build("elasticsearch",
model=ner_model,
score_threshold=score_threshold,
url=url, login=login)
case _:
print("Invalid NER mode")
return
Avec l’objet ner, on extrait les tags d’un texte
tags = nlp.get_entities(text)
Les tags sont retournés sous la forme d’un objet JSON
{
'LOC': ['Paris'],
'ORG': ['Pathé Palace', 'LED']
}
Afin de faciliter le lancement du script python, un script bash est fourni (scripts/crawler_post_process_ner.sh).
Les fichiers JSON enrichis seront dans le sous-répertoire « ner » du répertoire source.
Pour le mode spacy_llm, il est nécessaire de spécifier avec le paramètre « –api_key_file » un fichier qui contient une clé Open API. Le fichier est constitué d’une ligne dont le format est :
OPENAI_API_KEY:sk-proj-xxxxxxxxxxxx
Exemples de commandes pour chaque mode afin de générer une sortie sous la forme de fichiers CSV :
spaCy
$ ./scripts/crawler_post_process_ner.sh \
--input data/output/20-minutes-high-tech/clean \
--mode spacy \
--model fr_core_news_sm \
--output_csv_file tests/ner/spacy-sm.csv
$ ./scripts/crawler_post_process_ner.sh \
--input data/output/20-minutes-high-tech/clean \
--mode spacy \
--model fr_core_news_lg \
--output_csv_file tests/ner/spacy-lg.csv
spaCy-llm
$ ./scripts/crawler_post_process_ner.sh \
--input data/output/20-minutes-high-tech/clean \
--mode spacy_llm \
--api_key_file .secrets/openai_api_key.txt \
--config_file scripts/crawler_post_process_ner_spacy_llm.cfg \
--output_csv_file tests/ner/spacy_llm.csv
Transformers Hugging Face
$ ./scripts/crawler_post_process_ner.sh \
--input data/output/20-minutes-high-tech/clean \
--mode transformers \
--model Jean-Baptiste/camembert-ner \
--output_csv_file tests/ner/transformers.csv
Flair
$ ./scripts/crawler_post_process_ner.sh \
--input data/output/20-minutes-high-tech/clean \
--mode flair \
--model flair/ner-french \
--output_csv_file tests/ner/flair.csv
elasticsearch
$ ./scripts/crawler_post_process_ner.sh \
--input data/output/20-minutes-high-tech/clean \
--mode elasticsearch \
--model dslim__bert-base-ner \
--url http://localhost:9200 \
--login elastic:elastic \
--output_csv_file tests/ner/elasticsearch_dslim-bert-base.csv
$ ./scripts/crawler_post_process_ner.sh \
--input data/output/20-minutes-high-tech/clean \
--mode elasticsearch \
--model philschmid__distilroberta-base-ner-conll2003 \
--url http://localhost:9200 \
--login elastic:elastic \
--output_csv_file tests/ner/elasticsearch_philschmid.csv
Ce script Python à pour but de démontrer la méthode et la qualité des résultats pour chaque méthode. Il n’est pas optimisé pour les performances (pas de parallélisation). Voici quelques métriques suite à l’exécution de chaque méthode sur le corpus « JSON 20 Minutes High-Tech ».
| Méthode | Temps total | Entités distinctes extraites | GPU |
| Elasticsearch (dslim__bert-base-ner) | 460 secondes | 1430 | non utilisée |
| Elasticsearch (philschmid__distilroberta-base-ner-conll2003) | 482 secondes | 1699 | non utilisée |
| Spacy-llm | 1591 secondes 27 mn | 1683 | non utilisée |
| Spacy small | 26 secondes | 1621 | non utilisée |
| Spacy large | 43 secondes | 1211 | non utilisée |
| Transformer | 23 secondes | 997 | GPU : 45%GPU MEM : 600Mb – 7% |
| Flair | 82 secondes | 918 | GPU : 70%GPU MEM : 330Mb – 4% |
Les temps indiqués sont ceux d’une première exécution. Une seconde exécution pour elasticsearch ou spaCy-llm sont drastiquement inférieurs (quelques secondes) du fait de la mise en cache.
Afin de tenter de mesurer la qualité des résultats, je n’ai pas procédé à une extraction humaine des entités du corpus pour calculer exactement la précision et le recall de chaque méthode. J’ai mis en place un script qui consolide dans un fichiers CSV les entités nommées extraites par au moins N méthodes.
$ ./scripts/ner_extraction_quality.sh --input ./tests/ner --output_csv_file ./tests/ner_quality.csv --min_file 3
Suite à cette extraction des entités consolidées et si on accepte l’approximation qu’il s’agirait des entitées extraites humainement, le script calcule la précision et le recall des résultats de chaque méthode. Il faut utiliser le N le plus bas possible pour obtenir que des entités valides. J’ai retenu un N égale à 3. En effet, les entités extraites par seulement 2 méthodes sont souvent erronées.
elasticsearch_dslim-bert-base.csv
ORG: precision=0.421, recall=0.688
PER: precision=0.653, recall=0.674
LOC: precision=0.639, recall=0.297
elasticsearch_philschmid.csv
ORG: precision=0.524, recall=0.808
PER: precision=0.584, recall=0.878
LOC: precision=0.521, recall=0.589
spacy-lg.csv
ORG: precision=0.704, recall=0.555
PER: precision=0.757, recall=0.806
LOC: precision=0.552, recall=0.919
spacy-sm.csv
ORG: precision=0.619, recall=0.436
PER: precision=0.479, recall=0.79
LOC: precision=0.329, recall=0.914
spacy_llm.csv
ORG: precision=0.527, recall=0.761
PER: precision=0.439, recall=0.733
LOC: precision=0.557, recall=0.565
transformers.csv
ORG: precision=0.76, recall=0.681
PER: precision=0.88, recall=0.63
LOC: precision=0.76, recall=0.756
flair.csv
ORG: precision=0.794, recall=0.511
PER: precision=0.854, recall=0.759
LOC: precision=0.801, recall=0.789
Le recall indique le pourcentage d’entités consolidées trouvées par la méthode (note: pour N=7, la consolidation ne contient que des entités fournies par l’ensemble des méthodes et que donc le recall pour toutes les méthodes est toujours 1).
La précision indique le pourcentage des entités trouvées par la méthode et qui ont été retenues par la consolidation. Plus cette valeur est haute, moins des entités trouvées ont été rejetées (moins de faux positifs).
Note : Afin d’obtenir des valeurs plus précises, le script peut être appelé avec le paramètre –action. La valeur « concat » ne fait que calculer le fichier CVS de consolidation des entités nommées et la valeur « compute » ne fait que calculer les précision et recall à partir de ce fichier. Il est ainsi possible entre les deux phases de « nettoyer » le contenu du fichier consolider afin d’en retirer des faux positifs.
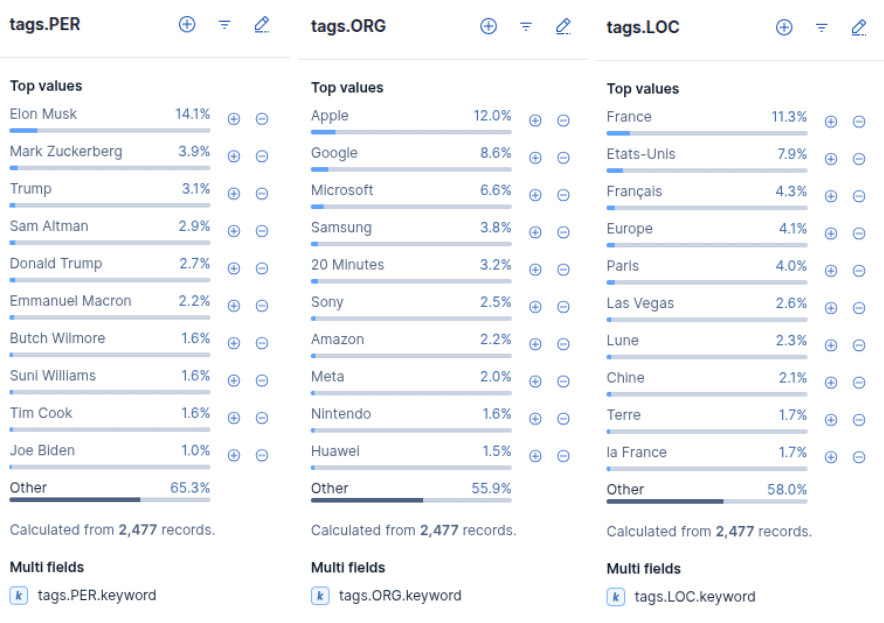
Visualisation dans Kibana
Afin de constater le résultat de l’extraction des entités nommées sur les fichiers JSON, on utilise pour l’exemple la méthode des transformers.
Enrichissement des fichiers JSON avec la méthode Transformers. Le résultat ne va pas dans un fichier CSV mais alimente le répertoire « data/output/20-minutes-high-tech/clean/ner » de fichiers JSON enrichis et prêts à être indexés.
$ ./scripts/crawler_post_process_ner.sh \
--input data/output/20-minutes-high-tech/clean \
--mode transformers \
--model Jean-Baptiste/camembert-ner
Indexation dans elasticsearch
$ ./scripts/elasticsearch_indexer.sh \
--input data/output/20-minutes-high-tech/clean/ner \
--index crawler-transformers-20-minutes-high-tech \
--host http://localhost:9200 \
--user elastic \
--password elastic \
--bulk_size 10
Création du Data View
$ curl -X POST "http://localhost:5601/api/data_views/data_view" \
-H "Content-Type: application/json" \
-H "kbn-xsrf: true" \
-d '{
"data_view": {
"title": "crawler-transformers-20-minutes-high-tech",
"name": "crawler-transformers-20-minutes-high-tech",
"timeFieldName": "publication_date"
}
}' \
-s \
-k -u elastic:elastic
L’affichage des agrégations des tags montre une meilleure qualité que le résultat obtenu précédemment par elasticsearch et le modèle philschmid__distilroberta-base-ner-conll2003.
Conclusions
Sur la qualité des résultats
Le jeu de documents utilisé n’est pas énorme, mais significatif. La méthode de validation quant à elle est certe approximative. Cependant, il me semble que les méthodes basées complètement ou en partie sur l’utilisation de LLM (spacy-llm, transformers) fonctionnent plutôt bien. Spacy avec un modèle large et Flair fonctionnent bien également. Par contre, je suis au regret de dire que elasticsearch avec les modèles proposés ne donne pas de bons résultats avec du Français.
Pour améliorer la qualité des résultats, il va falloir sélectionner les bons modèles selon le contexte et idéalement les optimiser.
Sur les performances
Il est la impossible de statuer suite à ces tests avec un script non optimisé et sur un ordinateur portable certe un peu puissant et équipé d’une GPU mais qui n’a pas vocation à exécuter ces tâches.
Les performances vont être dépendantes du codage des scripts d’extraction, du hardware utilisé et/ou des performances des API selon les plans choisis. En résumé, cela va être une question de budget.
Sur le choix du workflow d’extraction des entités
Outre la qualité des résultats et les performances, il s’agit de choisir entre extraction en amont de l’indexation ou lors de l’indexation. Mon avis est assez tranché. En effet je ne vois pas pourquoi faire réaliser cette opération lors de l’indexation par elasticsearch !
Voici un comparatif avantages / inconvénients des deux approches.
| Méthode | Avantages | Inconvénients |
| Extraction par elasticsearch | Mise en œuvre rapide, sans code spécifique Intégration native dans un pipeline d’indexation Maintenance centralisée dans Elasticsearch Compatible avec l’écosystème Elastic Security/Observability (via Fleet, ingestion, etc.) | Restreint à Elasticsearch (pas réutilisable dans d’autres contextes) Faible qualité des résultats pour le français avec les modèles proposés par défaut Recalcul nécessaire lors d’une réindexation ou d’un changement de pipeline Pas ou peu de contrôle sur le post-traitement des entités extraites Peu adapté à des corpus volumineux (risques de saturation du cluster) Peu de choix de modèles, surtout en français ou pour des domaines spécifiques |
| En amont de elasticsearch | Indépendant du moteur de recherche : compatible Elasticsearch, Solr, OpenSearch… Permet des enrichissements complexes (post-traitement, filtrage, normalisation…) Meilleure qualité sur des corpus spécialisés ou en français Large choix de modèles, ajustables ou fine-tunable Facile à rejouer ou adapter pour de nouveaux cas d’usage (exports, dashboards, etc.) Scalabilité contrôlée (traitement distribué, GPU, batch) | Nécessite un pipeline de traitement à part (hors cluster Elasticsearch) Implique du développement, du packaging et des tests supplémentaires Peut nécessiter une infrastructure GPU/CPU adaptée, selon le modèle Coûts potentiels en API (OpenAI, Hugging Face hosted, etc.) |
Sous une forme plus synthétique
| Critère | Elasticsearch | Hors Elasticsearch |
| Simplicité de mise en œuvre | ✔ | ✖ |
| Qualité des entités (français) | ✖ | ✔ |
| Adapté à d’autres usages que la recherche | ✖ | ✔ |
| Réutilisabilité / portabilité | ✖ | ✔ |
| Nécessite du code | ✖ | ✔ |
| Charge sur le cluster Elastic | ✖ | ✔ (aucune) |
| Coûts (API / infra dédiée) | ✔ (si self-hosted) | ✖ (potentiels) |
| Fine tuning possible | ✖ | ✔ |
| Choix de modèles | Limité | Large |
Dans cet article, nous avons comparé deux stratégies d’extraction d’entités nommées : directement au moment de l’indexation via Elasticsearch, ou en amont à l’aide de librairies NLP externes. Plusieurs outils open source ont été évalués, avec des scripts de test qui permettent de comparer la qualité des entités extraites et les performances associées.
Pour aller plus loin, plusieurs pistes sont a explorer :
- Sélection de modèles spécialisés adaptés à des domaines métiers (juridique, médical, …)
- Nettoyage linguistique plus poussé (suppression des élisions, regroupement d’entités équivalentes)
- Fine-tuning local de modèles existants sur des jeux de données annotés
- Évaluation manuelle ou semi-automatisée pour affiner les métriques de qualité (précision, rappel, F1)
Ces éléments permettront d’aller vers une extraction d’entités plus robuste, mieux intégrée à vos cas d’usages métiers.