
Cet article a pour but de présenter SolrCloud disponible depuis Solr 4.0 et couvre les aspects suivants :
- Décrire le principe de SolrCloud
- En quoi il permet d’atteindre des objectifs de haute disponibilité
- L’intégration d’une application avec SolrCloud
Dans un l’article « Mise en oeuvre de SolrCloud« , nous décrivons l’installation et la configuration d’un cloud de 4 noeuds avec un ensemble Zookeeper de 3 éléments.
Principe de SolrCloud
SolrCloud est un mode de fonctionnement particulier de Solr depuis la version 4 qui permet de distribuer les éléments du moteur Solr au travers de différents noeuds physiques (de différentes instances Solr installées sur des serveurs distincts). Le but de cette distribution est d’obtenir une solution performante, hautement disponible et évolutive.
Pour rappel, Solr peut toujours comme dans ses versions précédentes fonctionner en mode stand-alonesans mettre en oeuvre SolrCloud.
Sans SolrCloud
Sans SolrCloud, un ensemble de documents est indexé dans un index unique (ou un core) hébergé sur un seul serveur. Si le serveur n’est plus disponible, il n’est plus possible ni d’indexer, ni de rechercher. De plus, si les volumes de données à indexer ou si le nombre de requêtes augmentent, les performances se dégradent.
Toujours sans SolrCloud, pour pallier à ce problème, il est possible de mettre en place des index supplémentaires afin de répartir des données volumineuses dans différents index et de dupliquer un même index pour distribuer les recherches sur différents serveurs. On utilise deux mécanismes historiques de Solr : le sharding et la réplication.
Le problème de cette organisation distribuée sans SolrCloud est la gestion et le monitoring des différents éléments. Tout doit être fait “manuellement” :
- Lors de l’indexation, c’est l’application au dessus de Solr qui doit décider vers quel shard envoyer les données à indexer (rotation, sur la base d’une date, d’une meta-donnée, …). Si un des shards n’est plus disponible comment traiter le problème ?
- Les réplications de shards dans des shards mirroirs afin de pouvoir distribuer les recherches doivent être administrées manuellement avec la réplication standard de Solr. Si un des shards mirroirs n’est plus disponible temporairement comment mettre son contenu à niveau lorsqu’il redevient disponible ?
- Comment l’application connait l’instance Solr est à utiliser pour les recherches ?
- …
C’est à ces problèmes d’installation, d’administration, de routing, de monitoring et d’intégration que répond SolrCloud.
SolrCloud
SolrCloud est constitué de 2 éléments :
- Des noeuds Solr répartis sur des serveurs physiques distincts
- Zookeeper, un outil open-source utilisé pour être le contrôleur des tous les noeuds Solr (quel noeud fonctionne, quel noeud est un leader, quel noeud doit indexer une donnée, quand lancer une réplication, quel noeud est disponible pour une requête, …)
Terminologie
| Shard | Il s’agit de l’unité élémentaire d’une collection. Un shard héberge la totalité des donnée de la collection ou une sous-partie. Un shard est constitutué de 1 ou plusieurs slice (1 leader et ses replicas). |
| SolrCloud | Cluster de noeuds Solr utilisés conjointement en collaboration avec Zookeeper afin d’héberger un ensemble de collections. |
| Node | Composante physique (un serveur) d’un cluster SolrCloud. On peut aussi dire une instance Tomcat hébergeant Solr. Un noeud héberge et gère plusieurs core. |
| Slice | Composant d’un shard. Il s’agit d’un leader ou d’un replica. |
| Core | Une unité ou un index élémentaire Solr. Correspond à un des slices d’une collection. |
| Leader | Chaque shard possède un slice identifié comme leader. Les écritures se font en premier dans le leader puis sont synchronisées dans les replicas. Si le leader devient indisponible, un autre slice du shard est désigné comme leader. |
| Replica | Un slice d’un shard qui est la copie conforme des autres slices du shard. |
| Collection | Ensemble de documents dans lesquels on peut rechercher lors d’une requête. L’équivalent en SQL serait la table. Une collection peut n’être hébergée que dans un core ou répartie au travers de shards et de replicas. |
| Configuration | Ensemble de fichiers (schema.xml, solrconfig.xml, …) définissant le fonctionnement d’une collection. Chaque core (ou slice) d’une collection utilise la même configuration. Une configuration peut être utilisée par plusieurs collections. |
Zookeeper
Zookeeper est un élément essentiel de SolrCloud et c’est pourquoi il doit être répliqué afin d’être lui aussi toujours disponible. Lorsque plusieurs instances de Zookeeper fonctionnent conjointement, on parle d’un ensemble Zookeeper. Si Zookeeper ne fonctionne plus, SolrCloud ne fonctionne plus. Cette criticité fait que l’on utilise en général au moins 3 instances Zookeeper dans une architecture SolrCloud. Par contre, la bonne nouvelle est qu’une instance Zookeeper et un noeud Solr peuvent cohabiter sur le même serveur physique.
Pourquoi 3 et pas 2 instances pour gérer les cas de simple panne donc d’indisponibilité d’une seule instance Zookeeper ? Parce que pour que l’ensemble fonctionne, il faut que plus de la moitié des instances soient disponibles. Un nombre impair est conseillé et évidement pas 1 donc 3 sur des serveurs physiques distincts.
Cela donne une architecture comme celle-ci :
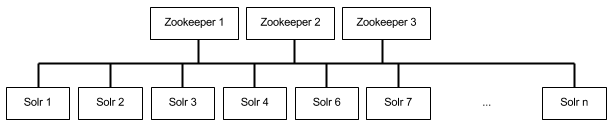
Zookeeper n’est pas très gourmand en ressources pour une fonctionnement avec Solr. Des processeurs dual-core avec 2 Go de RAM sont suffisants. Zookeeper ne risque pas d’être le goulot d’étranglement du cloud.
Collection
Dans SolrCloud, on ne parle pas d’un index mais d’une collection. Chaque collection est associée à une configuration qui est constituée d’un ensemble de fichiers de configuration Solr (shema.xml, solrconfig.xml, …). Les fichiers constituant une configuration sont chargés dans Zookeeper et on nomme cette configuration qui peut alors être partagée par plusieurs collections.
Une collection est répartie sur un ou plusieurs noeuds Solr du Cloud en fonction des besoins (haute-disponibilité, volumétrie des données, volumétrie des requêtes, …). Si on imagine trois collections dans notre cloud, on pourrait avoir ceci :

C’est Zookeeper qui se charge lors de la création d’une collection de :
- Décider sur quels noeuds sont distribués les éléments de la collection
- De piloter chaque noeuds pour la création des fichiers d’index de la collection
- De copier et synchroniser les fichiers de configuration vers les noeuds
La collection est donc découpée et répartie sur plusieurs noeuds. Lors de la création, on décide du nombre de shards et du nombre de réplicas. Un shard est un élément de découpage de l’index pour gérer la volumétrie des données. Les données sont réparties au travers des shards. Un replica est une copie d’un shard pour gérer la volumétrie des requêtes. Le réplica est également le composant essentiel de la haute disponibilité.
En fonction du nombre de shards et de replicas, on peut représenter une collection comme une matrice :

Quelques combinaisons types de collections :
| 1 shard | 2 à N shards | |
| 1 replica | Ne permet pas de garantir la haute disponibilité. Toute panne ou intervention de maintenance entraine l’indisponibilité en indexation en recherche | Permet un disponibilité en indexation si un shard n’est pas disponible. La recherche est partielle car elle porte sur un sous ensemble des données. Pas d’intégrité des données garantie si perte totale et reconstruction d’un shard. |
| 2 à N replicas | La collection reste totalement disponible en indexation et en recherche si un replica n’est pas disponible. Les performances sont dégradées. |
En cas d’indisponibilité d’un élément du cluster, la collection reste totalement disponible en indexation et en recherche. DE plus, les performances ne sont quasiment pas impactées. |
Remarque : Un shard est associé à ses replicas. Parmis eux, un est désigné comme leader. Si un d’eux est indisponible l’indexation et la recherche continuent à fonctionner. Si le leader devient indisponible, un nouveau leader est désigné et l’indexation et la recherche continuent à fonctionner. Lorsque l’élément redevient disponible, il est synchronisé et l’éventuel nouveau leader reste le leader.
Si la volumétrie des données le permet, la configuration minimale pour garantir une bonne disponibilité est la configuration à 1 shard et 2 replicas et la configuration minimale pour garantir une haute disponibilité et une haute intégrité des données est une configuration à 2 shards et 2 replicas.
Distribution des documents au travers des shards d’une collection
Par défaut, lors de l’indexation SolrCloud distribue les données au travers des shards d’une collection de manière à ce que les shards restent équilibrés en taille. Cependant, pour des besoins particuliers, il peut être intéressant de pouvoir contrôler la distribution des documents au travers des shards d’une collection. Ceci est possible et fera l’objet d’un prochain article.
Intégration avec une application (REST, API Java et PHP)
Il n’y a pas de point d’entré unique pour acceder à SolrCloud, mais le principe est que toutes les collections du cloud peuvent être accédées pour indexation et recherche via n’importe quel noeud de SolrCloud. L’application communique uniquement avec les noeuds Solr et n’a pas besoin de connaitre quoi que ce soit de Zookeeper.
http://xxx.xxx.xxx.xxx:yyyy/solr//select http://xxx.xxx.xxx.xxx:yyyy/solr//update
La recherche au travers de plusieurs collections compatibles (même schema.xml) est possible.
http://xxx.xxx.xxx.xxx:yyyy/solr//select?collection=col1,col2,col3&q=
C’est à l’application de gérer la non disponibilité d’un noeud et de basculer sur un autre au besoin.
http://192.168.0.24:9891/solr/collectionThree/select http://192.168.0.24:9690/solr/collectionThree/select http://192.168.0.24:7070/solr/collectionThree/select
De même, le load-balancing est à prendre en charge par l’application ou un load balancer tierce.
Remarque : Avec un cluster SolrCloud de 8 noeuds par exemple, le load-balancer tierce pourrait n’en connaitre que 3 ou 4 puisque tous noeuds du cluster est un point d’entré pour l’indexation et la recherche dans n’importe quelle collection répartie n’importe comment dans SolrCloud.
Cas particulier de SolrJ
SolrJ est l’API Java « officielle » de Solr.
Solrj inclut un mécanisme de communication avec Zookeeper pour connaitre les noeuds disponibles (il faut utiliser la classe CloudSolrServer). Il n’est donc pas nécessaire de mettre en place une gestion des noeuds non disponibles et un basculement automatique.
Solrj inclut un mécanisme de load-balancing basic sur le principe du round-robin (il faut utiliser la classe LBHttpSolrServerLoad).
Et pour PHP ?
Solarium « la librairie » PHP pour Solr ne dispose pas encore de mécanisme particulier pour exploiter SolrCloud en terme de load balancing et fail-over. Le mieux est d’utiliser une solution intermédiaire soft ou hard si on ne veut pas gérer cela dans le code PHP de l’application